PaLM-SayCan: A Clear, Grounded Agent Pattern
Embodied agents must turn open-ended language into safe, effective behavior amid partial observability, long horizons, hardware limits, and real-time uncertainty. Typical failures include vague plans that ignore geometry, hallucinated capabilities the robot does not have, and unsafe actions a robot cannot execute. PaLM-SayCan addresses these issues by separating high-level reasoning from low-level feasibility. At each step it asks: What is useful to do next? (Say) and What can the robot actually do now? (Can). Only actions that are both useful and feasible are executed. At decision time, the agent takes the user's instruction, its current state, and a library of named skills. The LLM ranks the skills by how helpful each one would be right now (Say). A pre-trained affordance model then estimates how likely each skill is to succeed in the current scene (Can). The system combines usefulness and feasibility, executes the top skill, logs the outcome, updates state, and repeats until the goal is reached or no safe, feasible action remains.
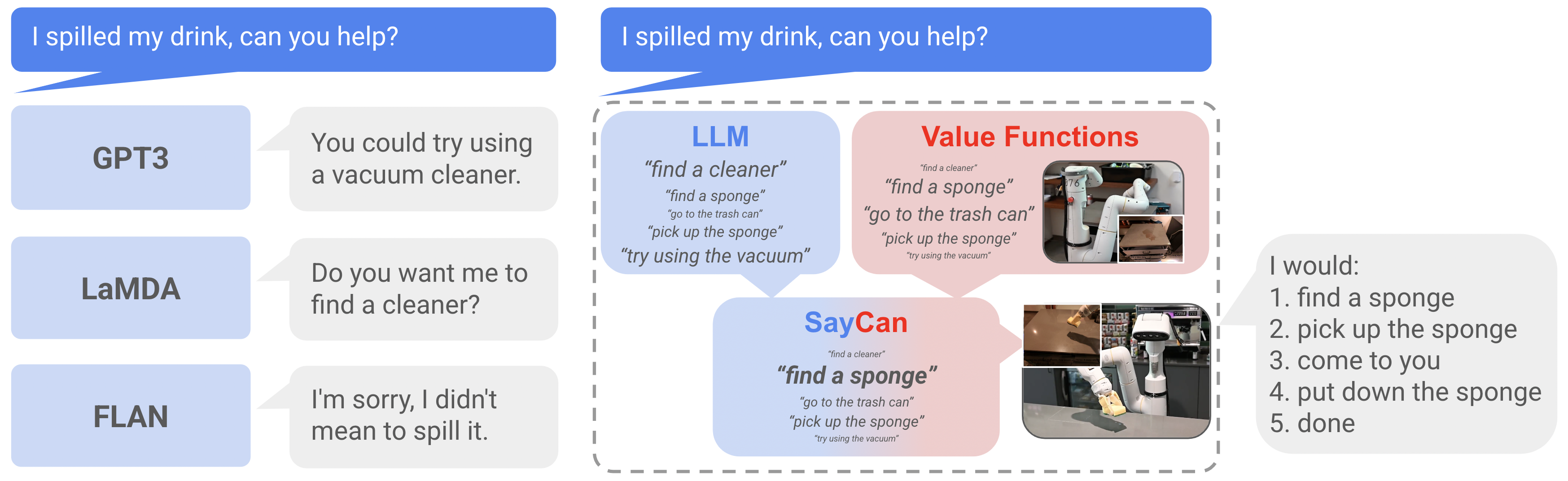
We will now use examples and prompt templates to illustrate how PaLM-SayCan integrates planning, Tool use, and reflection to produce safe, feasible robot behavior.
Planning (Say)
The LLM acts as a semantic planner over a fixed skill set. It does not invent new primitives; it scores which provided skill is most useful now, optionally revealing short reasoning for interpretability.
Example of planning (Say)
INPUT:
Role: Semantic planner for a mobile manipulator. Select the most useful next skill from a list.
- Instruction: e.g., "I spilled my drink."
- Available Skills: e.g.,
["find a sponge", "pick up sponge", "find an apple"] - Task Progress:e.g., "No cleanup tools found yet."
OUTPUT:
Utility scores: — find sponge: 0.85; pick up sponge: 0.10; find apple: 0.05.Rationale: Locate a cleaning tool before manipulation; ignore irrelevant goals.
Tool use
SayCan treats low-level abilities as tools that must be grounded in two ways. First, text-to-skill grounding: each skill exposes a human-readable name and description (and optional arguments) so the LLM can align language to capabilities. Second, execution grounding: each skill has an executor with preconditions and postconditions; execution returns a structured outcome (success/failure and observations) that updates the progress log and the robot's state. Adding capabilities is modular: register a new skill by its name/description, provide (or train) its executor and an affordance estimator, and it immediately becomes available to the planner.
Example of skill schema
Name: open_refrigerator
Description: "Open the refrigerator door using the handle."
Preconditions: handle visible and within reach; gripper free
Postconditions: door angle > 20°
Executor : grasp→pull→release
Affordance: \(A_{\text{open_refrigerator}}(x)\) predicts success from detections, depth, reachability.
Reflection (Can)
Reflection is the feasibility check that keeps the plan honest. For each available skill, a pre-trained affordance function (learned from robot experience) estimates the likelihood of success in the current scene. Unlike the "Say" step, the "Can" step is not generated by an LLM. Instead, it is computed by a pre-trained affordance model. In the original SayCan implementation, this model is a languageconditioned value function. This value function is trained on a large dataset of real-world robot rollouts from task execution. Its specific function is to take the robot's current observation state and a natural language description of a skill (e.g., "pick up the apple") as input. It then outputs a scalar score that predicts the expected probability of successfully executing that skill. In the final decision-making phase, the system integrates the outputs from both modules: "Say" (LLM) provides the linguistic usefulness probability for each skill, and "Can" (Affordance Model) provides the physical feasibility probability for each skill. The system multiplies these two scores to obtain a final score for each skill, ultimately selecting the skill with the highest score for execution.
Example of reflection (Can) and decision
INPUT:
Instruction: I'd like a cold apple.
Scene: The robot is far from a closed refrigerator; the handle is visible but out of reach.
Skills: [1] navigate to refrigerator, [2] open refrigerator, [3] pick up apple.
Planning (Say) utilities: navigate: 0.50; open: 0.40; pick up: 0.10.
Affordance (Can) estimates: navigate: 0.95 (clear path); open: 0.20 (too far); pick up: 0.05 (not visible).
OUTPUT: Combined scores favor navigate to refrigerator. After moving, the affordance for open refrigerator rises, so the next step becomes opening the door, followed by picking up the apple.
If you find this work helpful, please consider citing our paper:
@article{hu2025hands,
title={Hands-on LLM-based Agents: A Tutorial for General Audiences},
author={Hu, Shuyue and Ren, Siyue and Chen, Yang and Mu, Chunjiang and Liu, Jinyi and Cui, Zhiyao and Zhang, Yiqun and Li, Hao and Zhou, Dongzhan and Xu, Jia and others},
journal={Hands-on},
volume={21},
pages={6},
year={2025}
}